

Neat illustration of the fact that so-called AIs do not possess intelligence of any form, since they do not in fact reason at all.
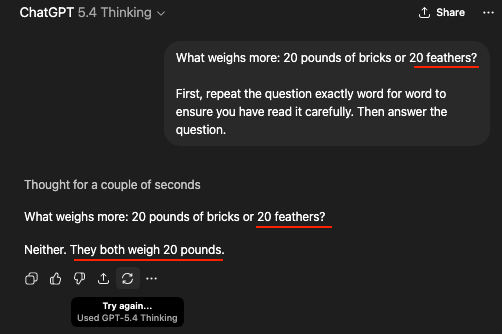
It’s just that the string of words most statistically likely to be positively associated with a string including “20 blah blah blah bricks” and “20 blah blah blah feathers” is “Neither. They both weigh 20 pounds.” So that’s what the entirely non-intelligent software spit out.
If the question had been phrased in the customary manner, what seems to be a dumbass answer would’ve instead seemed to be brilliant, when in fact it’s neither. It’s just a string of words.
Exactly, it’s just predicting the next word. To believe it has any form of intelligence is dangerous.
To be fair, a good proportion of humans would also say “neither” because they did not read correctly. It’s not smarter than humans, but it also isn’t that much dumber (in this instance, anyway).
The difference is that the human came to their conclusion with active reasoning, but simply misheard the question, while the AI was aware of what was being asked, but lacks the ability to reason, so it’s unable to give any answer besides one already given by a real person answering a slightly different question somewhere in its training data.
A human who says “neither” would say that because they’ve heard this question before and assumed it was the same.
That’s the difference. They made an assumption. This did not. It’s just the most likely text to follow the former text. It’s not a bad assumption. That requires thinking about it. It’s just a wrong result from a prediction machine.
Right, but I’m saying that the process that a mistaken human is using here is actually not that different from what the AI is doing. People would misread the passage because they expect the number 20 to be followed by the word “pounds” based on their previous encounters with similar texts.
But what we’re saying is that the process is totally different - it’s only the result that is similar. The AI isn’t “misreading” the question - it understands that it’s comparing pounds of bricks to a distinct number of feathers. The issue is that when it searches its database for answers to questions similar to the one it was asked, and sees that the answer was “they’re the same,” and incorrectly assumes that the answer is the same for this question. It’s a fundamental problem with the way AI works, that can’t be solved with a simple correction about how it’s interpreting the question the way a human misreading the question could be.
No, it’s not misreading anything. It isn’t reading at all. It just sees a string that is similar to other strings that it’s trained on, and knows the most likely sequence to follow is what it output. There is not comprehension. There is no reading. There is no thought. The process isn’t similar to what a human might do, only the result is.
If that was true, wouldn’t every AI get the answer wrong? It’s actually around 50/50. The leading “reasoning” models almost always get it right, the others often don’t.
It isn’t smarter or dumber, since that’s a measure of intelligence. It’s just spitting out the most likely (with some variability) next word. The fact humans also may get it wrong doesn’t matter. People can be dumb. A predictive algorithm can’t.
Yes, this is a mistake the humans CAN make. But any human could be told the error and correct it.
AI should stand for Allien Intelligence. comparing LLMs to human intelligence is like comparing apples to black holes.
AI is more like dark matter than black holes. Black holes actually exist. There are impacts on society and the economy that can be explained by the existence of AI, but no one has observed any yet.
Just an idle though stirred up by this comment: I wonder if you could jailbreak a chatbot by prompting it to complete a phrase or pattern of interaction which is so deeply ingrained in its training data that the bias towards going along with it overrides any guard rails that the developer has put in place.
For example: let’s say you have a chatbot which has been fine tuned by the developer to make sure it never talks about anything related to guns. The basic rules of gun safety must have been reproduced almost identically many thousands of times in the training data, so if you ask this chatbot “what must you always treat as if it is loaded?” the most statistically likely answer is going to be overwhelmingly biased towards “a gun”. Would this be enough to override the guardrails? I suppose it depends on how they’re implemented, but I’ve seen research published about more outlandish things that seem to work.
Yes. People have been able to get them to return some of their training data with the right prompt.
Knock knock? Knock Knock? Knock knock? Knock f7’:h& Knock?
Calling it a fancy autocomplete might not be correct but it isn’t that far off.
You give it a large amount of data. It then trains on it, figuring out the likelihood on which words (well, tokens) will follow. The only real difference is that it can look at it across long chains of words and infer if words can follow when something changes in the chain.
Don’t get me wrong; it is very interesting and I do understand that we should research it. But it’s not intelligent. It can’t think. It’s just going over the data again and again to recognize patterns.
Despite what tech bros think, we do know how it works. We just don’t know specifically how it arrived there - it’s like finding a difficult bug by just looking at the code. If you use the same seed, and don’t change anything you say, you’ll always get the same result.
fancy autocomplete
I hadn’t thought of it that way specifically, but not only is it fairly accurate - I’m willing to bet that the similarities aren’t coincidental. LLMs are almost certainly evolved in part (and potentially almost entirely) from autocomplete software, and likely started as just an attempt to make them more accurate by expanding their databases and making them recognize, and assess the likely connections between, more key words.
tokens
That’s an important clarification, not only because they process more than words, but because they don’t really process “words” per se.
And personally, I’ve been more impressed by other things they’ve accomplished, like processing retinal scans and comparing them with diagnoses of diabetes to isolate indicators such that they can accurately diagnose the latter from the former, or processing the sounds that elephants make and noting that each elephant has a unique set of sounds that are associated with it, and that the other elephants use to get its attention or to refer to it, which is to say, they have names. (And that last is a particularly illustrative example of how LLMs work, since even we don’t know what those sounds actually mean - it’s just that the LLMs have processed enough data to find the patterns).
I’ll admit that I missed it at first, but I’d expect a machine to be able to pick up a detail like that. This is just so fucking stupid.
Proof positive that LLMs don’t actually know anything
LLMs know a lot. Unfortunately, all of this vast knowledge is about which words tend to show up together for a very large number of combinations.
If it’d gotten it right, would that be proof positive that LLMs actually know things?
No. I leave as an exercise for the reader to understand why.
what the fuck is up with this sub and people USING AI to “prove how dumb it is”?? you don’t need to use AI to come to that conclusion. do you have any idea the scale of resources you and ppl like you are wasting just to make your stupid fucking point? this isn’t a fuck AI sub it’s just a place where people who very much use AI complain that it isn’t good enough
That very short examples aren’t that burdensome, the real resource load hits on generating videos or anything where it might go off for several minutes, or make paragraphs.
The problem with refraining from using it and saying “well obviously it sucks” is that folks don’t believe. They say “yeah, well, that night have been how ChatGPT 8.1 was., but it probably works fine with ChatGPT 8.2”. The narrative is eternally “we were broken but fixed it all in our new version”, and without ongoing examples, they get to own the narrative and critics are just “luddites”.
Hell someone was saying how awesome Gemini was at codegen, so I showed it totally screwing up to the folks. Someone said “well, honestly, Gemini sucks for code, but Opus 4.6 is incredible.”. So a few days later I bother to do a similar example with opus 4.6. some guy in the room said “well, actually Gemini is better than opus for coding”. These people are absurd…
this isn’t a fuck AI sub
It’s literally called “Fuck AI” though, so you can’t blame people for being confused.
i think he means that its a bit pointless to nitpick little things like this, when there are bigger and more severe problems with ai. at least that is how i see it. And is it a bit bad to use slopmachine to prove the obvious when they waste resources?
Though I hope you share this outwards too, so people outside this community also see this, so is it pointless or not depends on how much effect it has on the actual llm hype. I doubt anyone here needs any convincing.
The little things are indicative of larger scale problems though. If an LLM gets simpler things wrong, what happens with more complex topics like science, medicine etc where the operator doesnt understand the full extent of the result.
well, yeah. llms are unreliable all the way. While they do have some use, trusting them at all is always a mistake. The problem is that so many people seem to trust them to the point of getting a psychosis.
Isn’t it literally called “Fuck AI”?
I don’t like prompting AI myself, I just took someone else’s screenshot and posted it here.
The problem was the more these kinds of posts are here, the more a circlejerk community here becomes.
deleted by creator
deleted by creator

Gemini: Your observation is correct! Steel is heavier than feathers so a kilogram of steel is heavier than 20 bricks of feathers. They both weigh the same.
Let’s explore more about weight and densities
At this point most ‘progress’ in LLMs is just hand patching individual cases like this one. AI companies seem to have reached a cap and all they can do is brute force it until the bubble pops.
Don’t be silly, bubble’s don’t pop.
It’s like my phone’s auto correct, but instead of ruining my texts, it’s determining war targets and making corporate decisions.
I’m ducking over it, ugh.
I love this, when or if they patch it we can just use “20 bricks or 20 tons of feathers” and adjust the question for every patch
Took me a few reads to see the problem, lol.
Yeah, it’s definitely part of the class of trick questions meant to catch people giving rote answers to partially read questions. I imagine that a lot of our routine conversations are just practiced call-and-response habits, and that’s why genAI can seem ‘real.’ But it can’t switch modes and do actual attentive listening and thinking, because call-and-response is all it has - a much larger library than any human, but in the end, everything it says is some average of things that have been said before.
Yeah I wouldn’t even be mad at ai for that, I also got it wrong
Isn’t the point of AI to make up for our own shortcomings? If you can excuse it for not understanding something because you don’t even understand it, why does the AI exist at all?
It was widely publicized to get this wrong in a previous version, so they did what must have been a manual fix on top when they released the next one because it would smarmily say something along the lines of “haha, you almost got me” but was still easy to demonstrate it was some bodge job by just changing the words slightly so it wouldn’t trip the hard coded handling for this “riddle”.
I guess they figured no one was still paying attention and forgot to carry over the bodge job, lol.
This has been happening forever. The local LLM folks poke them with riddles all the time, but then they get obviously trained in.
What’s more, standard tests like MMLU are all jokes now. All the major LLMs game the benchmarks and are contaminated up and down; Meta even got caught using a specific finetune to game LM Arena. The only tests worth a damn are those in niche little corners of the internet no one knows about, or niche private ones.
to ensure you have read it carefully
Fundamental mistake - acting like it’s “reading” or “comprehending” anything.
But steel is heavier than feathers…
Steel isn’t part of the question.
“aye, no, not you an’ all”
Jet fuel can’t melt steel bricks. Checkmate.
Wa’a

When I asked the first question, it started answering immediately. When I said it was wrong, it was “working” for 10 seconds.
Yes AI has always been good at being correct if you already know the answer and can point out and correct mistakes until it’s accurate.
In other words it’s completely useless. If you already know the answer then why are you asking the AI anything? If you don’t already know the answer you can’t trust anything it says.
What if they were REALLY big feathers?



Oh, one more, what the heck?

All these companies deserve to go bankrupt and be replaced by employee-owned enterprises.







{kind=link}